Kvalitetsgranskning av databasmodell, SQL kod, databassäkerhet, backup/restore rutiner, utvecklingsrutiner och driftrutiner. Denna granskning syftar till…
Microsoft SQL Server är idag mycket mer än bara en databas. I licensen ingår, förutom själva databasen, ett antal andra komponenter som kan förenkla tillvaron om de används på rätt sätt. Ett av de viktigaste verktygen för överföring och automatisering av dataflöden mot externa och interna system är SQL Server Integration Services, SSIS.
Alla dessa komponenter ingår i SQL Server licensen:
| Databasmotorn (SQL Server) | Den komponent som i vardagligt tal kalls SQL Server eller databasen. Lagrar data i tabeller och databaser. | |
| Data Quality Services (DQS) | En “data-tvättmaskin” som kan rensa data från felaktigheter, dubbletter, felstavningar med mera. | |
| Analysis Services (SSAS) | Kärnan i BI-systemet. Här lagras data i summerad form i så kallade kuber (OLAP eller Tabular). | |
| Integration Services (SSIS) | Verktyget för integration, en kraftfull ETL-motor som mycket effektivt skyfflar data mellan databaser. Denna kan också användas för import och export av data till och från externa parter. | |
| Master Data Services (MDS) | Ett system för att hantera en “single point of truth” där man kan definiera en gång för alla hur man vill definiera sina objekt, exempel ett produktkategoriträd. Andra kringsystem som till exempel webben får sedan prenumerera på denna definition från MDS. | |
| Replication | En funktion som utför kopiering av hela eller delar av databaser mellan flera databasservrar enligt en prenumerationsmodell med publicerare (sändare av data) och prenumeranter (mottagare av data). | |
| Reporting Services (SSRS) | Ett rapportverktyg liknande Crystal Reports med egen webbserver alternativt integrerad med SharePoint. |
För dig som kund och licensägare kan det vara viktigt att känna till att alla dessa komponenter redan ingår i kostnaden för serverlicensen när du står inför ett beslut om investering i nya projekt inom något av dessa eller närliggande områden. Förutom att verktygen ingår, är det även ett faktum att SQL Server är en marknadsledande produkt vilket gör att det finns god tillgång på erfaren expertis som hanterar SQL Server.
Automatisering av dataflöden med hjälp av SSIS
I detta och följande blogginlägg tänker jag beskriva några av de implementationer av Integration Services (SSIS), som jag har driftsatt hos våra kunder för att förenkla deras vardag. Min förhoppning är att du som läser detta får idéer till hur just du skulle kunna göra på samma eller liknande sätt, eller kanske komma på någon helt ny tillämpning som du skulle vilja utföras med SSIS.
SSIS är, som nämns i tabellen, ett ETL-verktyg, där förkortningen ETL står för:
| E | Extrahera (Extract) | Hämta data från en datakälla. Datakällor behöver inte vara en tabell i en databas, utan kan vara en textfil, ett Excel-ark eller en XML-ström från en webbsida. Det finns nästan obegränsat med möjliga datakällor till SSIS. |
| T | Transformera (Transform) | Nästan alltid måste data överföras från källans format till det format man vill ha i målet. Till exempel måste ett amerikanskt datumformat MM/DD/YYYY justeras till ISO-standarden YYYY-MM-DD för att passa den svenska datum-format-standarden. |
| L | Ladda (Load) | Slutligen skall det transformerade datat laddas in till en destination. Inte heller detta måste vara en tabell i en databas, utan kan också vara till exempel en textfil. |
SSIS-verktyget är inte begränsat till att extrahera data från en tabell och ladda samma data till en annan tabell, utan det finns många fler strängar på SSIS-lyran. Det är bara din fantasi som sätter begränsningen för vad som är möjligt. Redan nu vill jag att du tänker lite på följande frågeställning:
Finns det någon repetitiv, manuell hantering av data i din organisation som borde kunna utföras med automatik?
| Scenario 1: Ekonomipersonal sammanställer manuellt excel-ark med information från flera olika system Stor tidsåtgång för manuell inhämtning av information och data är ofta ett tecken på dåligt integrerade informationssystem. En ofta förekommande funktion av repetitivt slag brukar man kunna finna på företagets ekonomiavdelning, där ekonomipersonal sitter och manuellt sammanställer Excel-ark med information från flera system; ekonomi, personal, lager och inköp för att få fram en totalbild på kostnader och intäkter för hela företaget. Inte sällan uppstår fel i processen på grund av den mänskliga faktorn; att man råkar klistra in celler över formler, eller att formler hamnar snett i förhållande till varandra. Det kan också lätt uppstå dubbletter eller felformateringar. Excel är ”bra” på att identifiera innehåll i kolumner felaktigt. Ett annat exempel skulle kunna vara att man går in manuellt via webbgränssnitt till Riksbanken för att hämta dagens växelkurser, eller till banken för att hämta de senaste kundinbetalningarna. |
Datainhämtning oberoende av tidpunkt och utan manuella fel
Gemensamt för scenario 1 ovan är att all hantering som beskrivs skulle kunna implementeras som automatiska SSIS-jobb, där sammanslagning av all information skulle kunna ske helt automatiskt i databasen på schemalagda tider. En sådan implementation skulle innebära följande fördelar:
• Risken för manuella fel minskar
• Personalen får tid till att utföra egentliga ekonomisysslor istället för datainsamling
• Personberoenden minskar
• Inhämtande av data kan ske mycket oftare, även nattetid och utan att belasta personalen.
Exemplet ovan är typiskt för en typ av problem som lämpar sig alldeles utmärkt att lösa med en SSIS-implementation. Det enda som behövs är att någon SSIS-kunnig person sätter upp miljön åt dig.
Ett enkelt SSIS-paket ser ut så här:
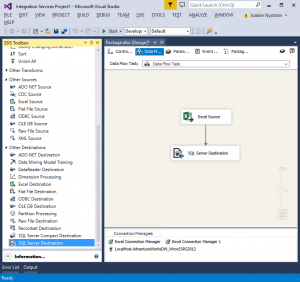
I bilden ovan framgår att:
1. Utvecklingsmiljön för SSIS är Visual Studio.
2. Utveckling sker i ett grafiskt gränssnitt som visar källor (Sources) och destinationer (Destinations), samt pilar som binder samman dessa, och som visar i vilken riktning som flödet går. I bilden visas ett enkelt flöde från ett Excel-ark till en (tabell i en) SQL Server-databas.
I vänstra halvan av fönstret visas vilka källor och destinationer som ingår ”out-of-the-box” i produkten. Det finns också en stor tredjeparts-marknad med tillägg till dessa, både som frivaror och till försäljning.
En av mina principer när det gäller utveckling i SSIS visas tydligt i bilden:
Man ska tydligt kunna se på en sida hur ett flöde ser ut!
Minimera belastningen på källsystemet och gör enkla SSIS-paket
I samtliga kundfall som jag har stött på har SSIS fått lov att dela resurser (processor + minne) med SQL Server-tjänsten; det vill säga att de ligger på samma server. Detta betyder att SSIS-tjänsten inte har tillgång till allt internminne på servern. Det går dock utmärkt att separera tjänsterna på flera servrar i större implementationer.
SSIS är en tjänst som arbetar nästan helt och hållet i minnesstrukturer, så målet är då att reducera minnesåtgången så mycket som möjligt. Därför är det bra att så fort och enkelt som möjligt få in data i SQL Server till en måltabell. Denna tabell utgör en ”råversion” av datamängden som vi sedan modellerar om i SQL-kod för att utföra eventuellt nödvändiga transformationer. Det betyder att ett viktigt mål gällande SSIS-utveckling skall vara enkelhet.
Vi vill få tag i data från källan så snabbt och enkelt som möjligt, bland annat eftersom vi inte vill belasta källan i onödan; den kan ju utgöra en del av en mycket aktiv produktionsdatabas!
I detta fall arbetar vi efter en ELT-liknande process. Initialt en snabb Extract + Load, och först därefter Transformering av data inuti SQL Server. På så sätt får vi ett system som inte innehåller så mycket kod ”gömt” i SSIS-paket, utan det mesta finns dokumenterat i transformations-procedurer skrivna i T(ransact)-SQL i måldatabasen. Detta innebär även att underhållet av SSIS begränsas, eftersom utveckling av kod koncentreras till databasen och T-SQL, vilket i sin tur reducerar kostnaden för underhåll av hela systemet.
Vi fortsätter om ett tag med nya scenarios och diskussioner!