Klustrade tabeller är det som rekommenderas i alla typer av applikationer. Detta är vad som händer…
När man har en tabell utan klustrat index kallas det för Heap. Heapar anses inte bra ur prestandasynvinkel, men de är ofta förekommande även i köpta applikationer.
Detta händer i en Heap vid de vanliga operationerna:
INSERT – Den nya raden placeras på den första sidan i tabellen där den får plats. Finns ingen sida där det finns plats så skapas en ny sida sist i tabellen.
UPDATE – Om man uppdaterar en kolumn som är av typen varchar och har samma längd på den uppdaterade strängen som den lagrade, så sker endast uppdatering av innehållet. Om man däremot uppdaterar en varchar kolumn med en sträng som är längre än den tidigare och det inte finns plats på sidan att spara den nya raden som har blivit längre så ersätts utrymmet i aktuell sida med en pekare (Forwarding) till en ny sida dit raden flyttas.
DELETE – Raden markeras bara som borttagen
SELECT – För de flesta frågor måste hela tabellen läsas.
Varför Forwarding?
Varför pekar man om den befintliga posten till en ny sida istället för att ta bort allt från den gamla sidan och flytta allt ihop?
Om man flyttade alltihop så skulle man behöva uppdatera alla index (icke klustrade) som finns på tabellen. Genom detta förfarande minskar man kostnaden för en uppdatering.
Om vi tittar på ett exempel:
-- Create test tables
Create Table Tab_NonClustered (
RowNr int,
ColChar char (100),
ColVarChar varchar(1000));
go
Create nonclustered index IX_Tab_NonClustered_RowNr on Tab_NonClustered (RowNr);
Go
-- Load data
Set Nocount On;
Declare @i int;
Select @i = 1;
While (@i < 11)
Begin
Insert Into Tab_NonClustered
Values (@i, 'hello', replicate ('a', 500));
Set @i = @i + 1;
End
-- Check the Number of pageg och forwarded records
Select index_type_desc, alloc_unit_type_desc, page_count, Fragment_Count, forwarded_record_count
From sys.dm_db_index_physical_stats(DB_Id(),
Object_Id('Tab_NonClustered'), NULL, NULL, 'DETAILED');
<pre>
Vi har data bara på en sida och inga rader flyttade:

</pre> -- Check number of rows/page Select 'Tab_NonClustered' Tabell, SubString([Physical RID], 4, 5) Page, Count(*) [Rader/Page] From (Select %%physloc%% rowid, sys.fn_PhysLocFormatter (%%physloc%%) AS [Physical RID] From Tab_NonClustered ) x Group by SubString([Physical RID], 4, 5) order by 2; <pre></pre>
Vi har 10 rader på sida 12796 (du får annat sidnummer)
![]()
-- Check Datapage info -- Man måste slå på traceflaggan 3604 DBCC TRACEON(3604) GO -- Här måste du ange ditt database namn istället för SQLService_Div dbcc page([SQLService_Div],1,11552,3)
Här ser vi att Slot2 har en PRIMARY_RECORD (Slot 2 startar på rad 145):
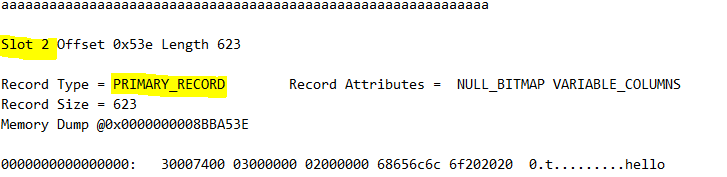
</pre> Set statistics io on Set statistics time on Select * from Tab_NonClustered <pre>
Vi får bara 1 Logical reads:
![]()
--Add 1500 char to a column
Update Tab_NonClustered set ColVarChar = ColVarChar + replicate ('b', 1500)
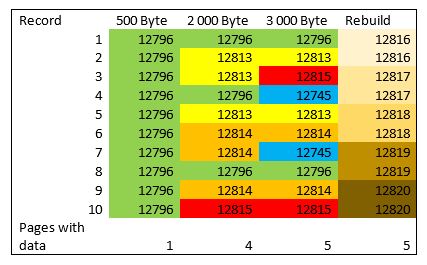
Om vi nu kontrollerar hur många sidor tabellen är nu så ser vi att den ökat till 4. Dessutom har vi fått 7 Forwarded_record_count.

Men tittar vi på hur många rader vi har på sidorna får vi bara upp 1 sida och den ska innehålla 10 rader (samma som tidigare). Problemet är att nu är ju raderna 2115 Bytes långa vilket inte får plats på en sida som bara kan rymma 8060 Bytes data. Den tittar dock bara på en sida för att hitta antalet rader, att raderna ligger på andra sidor tas inte hänsyn till här.
![]()
Tittar vi nu hur sidan ser ut så hittar vi att slot 2 har flyttats till sida 12813 slot 1. (slot 2 på rad 325):
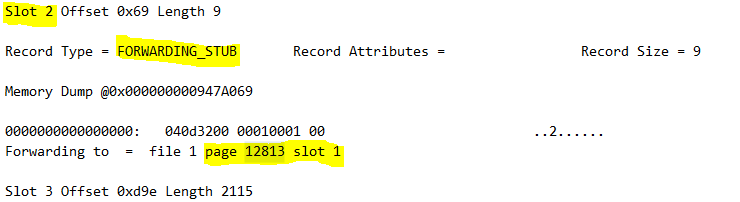
På sida 12813 hittar vi:
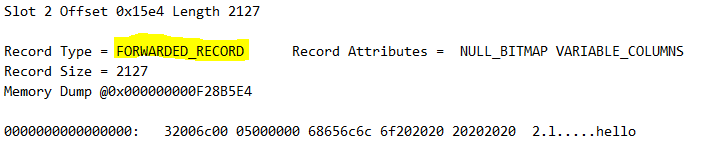
Det innebär att för att hitta denna rad måste man leta i på två sidor vilket inte är så lyckat ur prestanda synvinkel.
Select * from Tab_NonClustered
Vi får bara 11 Logical reads:![]()
Vad händer om man förlänger kolumnen ännu mer, så att den flyttade raden inte får plats på sin nya sida?
--Add 1000 char to a column
Update Tab_NonClustered set ColVarChar = ColVarChar + replicate ('c', 1000)

Och selecten ger ytterligare några logical reads:
![]()
Man kan justera ’hoppandet’ mellan sidor genom att köra en rebuild.
</pre> -- Rebuild av tabellen Alter Table Tab_NonClustered ReBuild <pre>
Det ger inte färre sidor men nu har man inga ’forwarding_stub’ utan alla index är fixade så att de pekar direkt på rätt sida. Hela tabellen har ju byggts om så all information har flyttat till nya sidor.
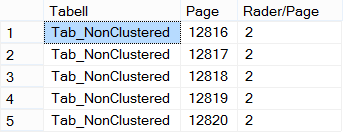
Här ser man vilken page resp. rad ligger på i de olika stegen.
Nästa gång tittar vi på vad som händer i motsvarande för clustrade tabeller.