The question is simple: is there any difference between the performance of the different service…
As you already know by now, indexes are very important for SQL server performance, and finding the best indexes can be hard and time consuming. There are some tools that can help you or make things even worse. Some of the tools you can use are included in the SQL server platform, like:
- Database engine tuning advisor
- Missing index DMV:s
- Estimated / Actual Execution plan
They all have capabilities to give you suggestions of indexes, but they also have their issues. I will not describe these features in detail, but if you use these tools to implement all the suggested indexes you can even decrease the performance. They give you suggestions and you still have to test the performance before and after.
|
Tool |
Benefit |
Concern |
|
Database Tuning advisor |
Give you good suggestions |
-Uses a lot of resources -Give you a lot of similar indexes |
|
Missing indexes |
Give you good suggestions based on execution plans from the cache |
Give you a lot of similar indexes Gives you suggestion of indexes that already exists because one of the columns need a different sort order, but there is no suggestion of the sort order |
|
Estimated or Actual Execution plan |
Give you the suggestion of index of the query you are running right now |
Doesn’t display all the missing indexes for the query and you have to implement the index and execute one more time to get the next suggestion. The index suggestion is not displayed for the actual statement that needs the index |
There is a connect item for the missing index DMV, please vote for it at :
The problem with the estimated or actual execution plan is that you can only see one suggestion at the time and it’s not correlated with the statement.

In SQL server 2012 you can get all the missing indexes in the estimated or actual execution plan GUI, but not in SQL server 2008. BUT you can find all the missing indexes in the execution plan XML, just right click the exection plan and click the “Show Execution Plan XML” menu item, search the XML for MissingIndex and you’ll find all of them! It’s only a GUI issue, all the information is in the XML plan.
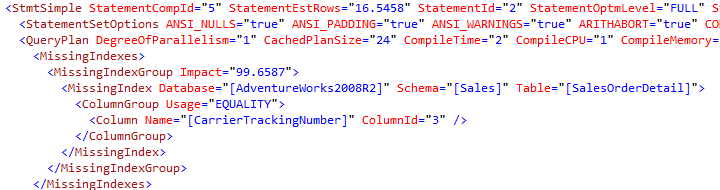
How can you use this information? Well, if you now how to write some XQueries you can actually list all the missing indexes with the SQL statement attached. With this list you can investigate your index based on the statement that needs it. You can actually query the cache for all execution plans that have missing index suggestions, but beware, it is a heavy query that can cause performance issues during the execution.
The best solution is to pick the worst performing queries from the cache by using the sys.dm_exec_procedure_stats DMV and store the result in a temp table with an XML index.
Using XML in SQL server can be tricky unless you are very skilled in XQuery and I would like to help you a little bit to get started. In the following code, I have removed some interesting statements for other interesting information in the XML plan.
/*
SELECT top 10 OBJECT_NAME(.[object_id], .[database_id]), DB_NAME(database_id), *
FROM sys.dm_exec_procedure_stats ps
CROSS APPLY sys.dm_exec_query_plan(ps.plan_handle) qp
order by ps.[last_logical_reads] desc
*/
CREATE PROCEDURE DBO.[spCheckSP](@dbName sysname, @schemaName sysname, @procedureName sysname)
AS
-- +----------------------------------------------------------------------------------------------------------------
-- ! O b j e c t [ADMIN].[spCheckSP}
-- ! R e t u r n s INT
-- ! P a r a m e t e r s Name, DataType, Description
-- + =========================================================================================
-- ! @dbName sysname
-- ! @schemaName sysname
-- ! @procedureName sysname
-- + ---------------------------------------------------------------------------------------------------------------
-- ! O b j e c t i v e
-- + ---------------------------------------------------------------------------------------------------------------
-- ! S A M P L E
-- ! EXEC [ADMIN].[spCheckSP] 'AdventureWorks2008R2', 'Sales', 'uspGetBillOfMaterials'
-- + ---------------------------------------------------------------------------------------------------------------
-- ! H i s t o r y Date Who What
-- +========== ===== =========================================================================
-- ! 2011-01-26 HAWI Initial version ...
-- + ---------------------------------------------------------------------------------------------------------------
SET NOCOUNT ON;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
DECLARE @objectName SYSNAME = @dbName + '.' + @schemaName + '.' + @procedureName
SELECT ProcedureName = @objectName;
SELECT
query_plan = CONVERT(XML,qp.query_plan),
ps.*
INTO #tmpPlan
FROM sys.dm_exec_procedure_stats ps
CROSS APPLY sys.dm_exec_query_plan(ps.plan_handle) qp
WHERE OBJECT_ID = OBJECT_ID(@objectName)
AND database_id = DB_ID(@dbName);
SELECT * FROM [#tmpPlan];
----------------------------------------------------------------------------------------------------------------
-- get missing index stats
----------------------------------------------------------------------------------------------------------------
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
,cteMissingIndexes
AS (
SELECT tp.query_plan --, cp.usecounts
FROM #tmpPlan tp
WHERE tp.query_plan.exist('//MissingIndex')=1
)
SELECT
databaseName = stmt.value('(.//MissingIndex/@Database)[1]', 'sysname'),
[schemaName] = stmt.value('(.//MissingIndex/@Schema)[1]', 'sysname'),
[tableName] = stmt.value('(.//MissingIndex/@Table)[1]', 'sysname'),
sql_text = stmt.value('(@StatementText)[1]', 'VARCHAR(4000)'),
impact = stmt.value('(.//MissingIndexGroup/@Impact)[1]', 'FLOAT'),
stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="EQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS equality_columns
,stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="INEQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS inequality_columns
,stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="INCLUDE"
return string($column/@Name)
').value('.', 'varchar(max)') AS include_columns
,pmi.query_plan
FROM cteMissingIndexes pmi
CROSS APPLY pmi.query_plan.nodes('//StmtSimple') AS qp(stmt)
WHERE stmt.exist('.//MissingIndex/ColumnGroup[@Usage="EQUALITY"]')=1 OR stmt.exist('.//MissingIndex/ColumnGroup[@Usage="INEQUALITY"]')=1
UNION ALL
SELECT
databaseName = stmt.value('(.//MissingIndex/@Database)[1]', 'sysname'),
[schemaName] = stmt.value('(.//MissingIndex/@Schema)[1]', 'sysname'),
[tableName] = stmt.value('(.//MissingIndex/@Table)[1]', 'sysname'),
sql_text = stmt.value('(@StatementText)[1]', 'VARCHAR(4000)'),
impact = stmt.value('(.//MissingIndexGroup/@Impact)[1]', 'FLOAT'),
stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="EQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS equality_columns
,stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="INEQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS inequality_columns
,stmt.query('for $group in .//ColumnGroup
for $column in $group/Column
where $group/@Usage="INCLUDE"
return string($column/@Name)
').value('.', 'varchar(max)') AS include_columns
,pmi.query_plan
FROM cteMissingIndexes pmi
CROSS APPLY pmi.query_plan.nodes('//StmtCond') AS qp(stmt)
WHERE stmt.exist('.//MissingIndex/ColumnGroup[@Usage="EQUALITY"]')=1 OR stmt.exist('.//MissingIndex/ColumnGroup[@Usage="INEQUALITY"]')=1;
As you can see, you need to query two different nodes (StmtSimple and StmtCond) to get all the missing indexes. The result might look something like this when you pass the name of a stored procedure into this procedure I gave you.

In this case, I have to statements that need an index each and I can investigate the query to see if I need to change something in the query or if I should create the index. The Impact is an estimate on how many percent improvement the index would give you, but it should be handled as a guess based and it is based on statistics. (read my other blog posts about statistics to understand why this not to be trusted.)
If you give me positive feedback (on twitter or as a comment) of the blog post, I’ll consider to post some other blog posts with other interesting parts of the XML plan and queries to extract it.
/Håkan Winther
twitter: @h_winther