Just wanted to write up a SSMS tip I’ve found really useful over the years…
Introduction
In my previous post I used SQL Profiler to investigate how the Data Classification feature works under the covers and we also found out a couple more shortcomings
(doesn’t parse XML data, tries to and fails adding extended properties to in-memory tables).
But we did establish that it is possible to add the relevant extended property tags directly from the backend and that the SSMS reports and features will pick them up and display them as usual.
In this post I will create a proof of concept for creating our own dictionary table and using these custom values (in Swedish naturally) to provide data classification capabilities for databases that have column names defined in Swedish (or whatever language you add to your dictionary table). I will also try and produce remedies to the limitations in the feature that I found last time.
OK – first of all we will need a couple of tables with column names in Swedish, here’s a very basic example (Person & Företag – which translates to Person & Company).
-- Add a couple of tables with Swedish table and column names
IF Object_id('dbo.Person') is not null
BEGIN
Drop Table dbo.Person
END
Create Table dbo.Person
(
Efternamn nvarchar(80) NOT NULL
,Förnamn nvarchar(80) NOT NULL
,Födelseort nvarchar(80) NOT NULL
,medborgarskap nvarchar(80) NOT NULL
,Födelseland nvarchar(80) NOT NULL
,Födelsedatum datetime NOT NULL
,Adress nvarchar(80) NOT NULL
,Postadress nvarchar(80) NOT NULL
,Postnummer varchar(10) NOT NULL
,Personnummer varchar(10) NOT NULL
,Kön varchar(8) NOT NULL
)
IF Object_id('dbo.Företag') is not null
BEGIN
Drop Table dbo.Företag
END
Create Table dbo.Företag
(
Namn nvarchar(100) NOT NULL
,Adress nvarchar(80) NOT NULL
,Postadress nvarchar(80) NOT NULL
,Postnummer varchar(10) NOT NULL
,OrgNummer varchar(10)
)
Dictionary
Then we will just steal borrow the dictionary table which our trace last time revealed, as an aside I believe that adding a language column and then filtering to english plus the language of the database collation would be a shortcut to much better performance (and fewer false positives).
Now we just need to populate the dictionary, I will take some of the english terms and translate them to swedish. I can’t resist leaving in the spelling mistake %mainden%name%
– I guess this rule won’t fire very often.
The following rows / rules should give us enough to test with a full GDPR scan would obviously require a fuller dictionary.
('%användarnamn%' ,'Credentials','Confidential' ,1),
('%lösenord%' ,'Credentials','Confidential' ,1),
('%password%' ,'Credentials','Confidential' ,1),
('%emejl%' ,'Contact Info','Confidential - GDPR' ,0),
('%epost%' ,'Contact Info','Confidential - GDPR' ,0),
('%e-mejl%' ,'Contact Info','Confidential - GDPR' ,0),
('%e-post%' ,'Contact Info','Confidential - GDPR' ,0),
('%efter%namn%' ,'Name','Confidential - GDPR' ,0),
('%för%namn%' ,'Name','Confidential - GDPR' ,0),
('%familjenamn%' ,'Name','Confidential - GDPR' ,0),
-- from original dictionary - to show spelling mistake - this isn't how you spell maiden !!!
('%mainden%name%' ,'Name','Confidential - GDPR' ,0),
('%flick%namn%' ,'Name','Confidential - GDPR' ,0),
('%adress%' ,'Contact Info','Confidential - GDPR' ,0),
('%telefon%' ,'Contact Info','Confidential - GDPR' ,1),
('%mobil%' ,'Contact Info','Confidential - GDPR' ,1),
('%postnummer%' ,'Contact Info','Confidential - GDPR' ,1),
('%person%nummer%' ,'National ID','Confidential - GDPR' ,1)
After this come the Information type and Sensitivity label tables (@InfoTypeRanking @SensitivityLabel), the entries are the same as before but I have added an extra column with the datatype uniqueidentifier to these tables as these are required by the data classification page (but not the report) we will add these as extended properties.
DECLARE @InfoTypeRanking TABLE
(
info_type NVARCHAR(128),
info_type_guid uniqueidentifier default newid(),
ranking INT
)
-- If we get multiple matches we will apply the lowest ranking first
-- So if a column matches on both Name and CreditCard it will be classified as Name
-- Your priorities may differ from Microsoft's
INSERT INTO @InfoTypeRanking (info_type, ranking)
VALUES
('Networking', 100),
('Contact Info', 200),
('Credentials', 300),
('Name', 400),
('National ID', 500),
('SSN', 600),
('Credit Card', 700),
('Banking', 800),
('Financial', 900),
('Health', 1000),
('Date Of Birth', 1100),
('Other', 1200)
DECLARE @SensitivityLabel TABLE
(
sensitivity_label NVARCHAR(128),
sensitivity_label_guid uniqueidentifier default newid()
)
Insert @SensitivityLabel (sensitivity_label) select distinct sensitivity_label from @Dictionary
If you want to know more about extended properties I refer you to the following article
https://www.red-gate.com/simple-talk/sql/database-delivery/scripting-description-database-tables-using-extended-properties/
Note that Phil is using JSON formatting for his extended properties, by doing this he can store multiple properties in a single extended property and this allows one to store a single extended property per column holding all of the values (but using this technique would create problems with compatibility with versions earlier than SQL Server 2016 and is the probably explanation why ).
Calculate Results
I populate the @ClassifcationResults table using the exact Microsoft code now all we need to do is use a common table expression to generate the calls to sp_addextendedproperty to tag the columns that have been identified. So simply copy the output calls and paste into a new SSMS window connected to the right database and execute.
DECLARE @ClassifcationResults TABLE
(
schema_name NVARCHAR(128),
table_name NVARCHAR(128),
column_name NVARCHAR(128),
info_type NVARCHAR(128),
sensitivity_label NVARCHAR(128),
ranking INT,
can_be_numeric BIT
)
INSERT INTO @ClassifcationResults
SELECT DISTINCT S.NAME AS schema_name,
T.NAME AS table_name,
C.NAME AS column_name,
D.info_type,
D.sensitivity_label,
R.ranking,
D.can_be_numeric
FROM sys.schemas S
INNER JOIN sys.tables T
ON S.schema_id = T.schema_id
INNER JOIN sys.columns C
ON T.object_id = C.object_id
INNER JOIN sys.types TP
ON C.system_type_id = TP.system_type_id
LEFT OUTER JOIN @Dictionary D
ON (D.pattern NOT LIKE '%[%]%' AND LOWER(C.name) = LOWER(D.pattern) COLLATE DATABASE_DEFAULT) OR
(D.pattern LIKE '%[%]%' AND LOWER(C.name) LIKE LOWER(D.pattern) COLLATE DATABASE_DEFAULT)
LEFT OUTER JOIN @infoTypeRanking R
ON (R.info_type = D.info_type)
WHERE (D.info_type IS NOT NULL ) AND
NOT (D.can_be_numeric = 0 AND TP.name IN ('bigint','bit','decimal','float','int','money','numeric','smallint','smallmoney','tinyint'))
; WITH Class AS
(
SELECT
ROW_NUMBER() OVER (ORDER BY MR.schema_name, MR.table_name, MR.column_name) as rnum,
CR.schema_name AS schema_name,
CR.table_name AS table_name,
CR.column_name AS column_name,
OBJECTPROPERTY(OBJECT_ID(N''+CR.schema_name+'.'+CR.table_name+''),'TableIsMemoryOptimized') as IsInMemory,
CR.info_type AS information_type_name,
convert(varchar(50), ITR.info_type_guid) as info_type_guid,
CR.sensitivity_label AS sensitivity_label_name,
convert(varchar(50), SL.sensitivity_label_guid) as sensitivity_label_guid
FROM @ClassifcationResults CR
INNER JOIN
(
SELECT
schema_name,
table_name,
column_name,
MIN(ranking) AS min_ranking
FROM
@ClassifcationResults
GROUP BY
schema_name,
table_name,
column_name
) MR
ON CR.schema_name = MR.schema_name
AND CR.table_name = MR.table_name
AND CR.column_name = MR.column_name
AND CR.Ranking = MR.min_ranking
JOIN @InfoTypeRanking ITR ON
ITR.info_type = CR.info_type
JOIN @SensitivityLabel SL ON
SL.sensitivity_label = CR.sensitivity_label
)
-- uncomment and run the below if you want a report
-- rather than the calls to add the extended properties
--SELECT
--C.schema_name,
--C.table_name,
--C.column_name,
--OBJECTPROPERTY(OBJECT_ID(N''+C.schema_name+'.'+C.table_name+''),'TableIsMemoryOptimized') as IsInMemory,
--C.info_type AS information_type_name,
--C.sensitivity_label AS sensitivity_label_name,
SELECT rnum, 1 as subsort,
'EXEC sp_addextendedproperty @name = N''sys_information_type_name'', @value = '''+C.information_type_name+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';' as xp1
FROM Class C
UNION ALL
SELECT rnum, 2,
'EXEC sp_addextendedproperty @name = N''sys_information_type_id'', @value = '''+C.info_type_guid+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
UNION ALL
SELECT rnum, 3,
'EXEC sp_addextendedproperty @name = N''sys_sensitivity_label_name'', @value = '''+C.sensitivity_label_name+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
UNION ALL
SELECT rnum, 4,
'EXEC sp_addextendedproperty @name = N''sys_sensitivity_label_id'', @value = '''+C.sensitivity_label_guid+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
-- We can't add extended properties to InMemory tables so lets filter those out
WHERE IsInMemory = 0
order by rnum asc, subsort
Now when I open the data classification window I see the matching columns correctly tagged and similarly within the report. QED
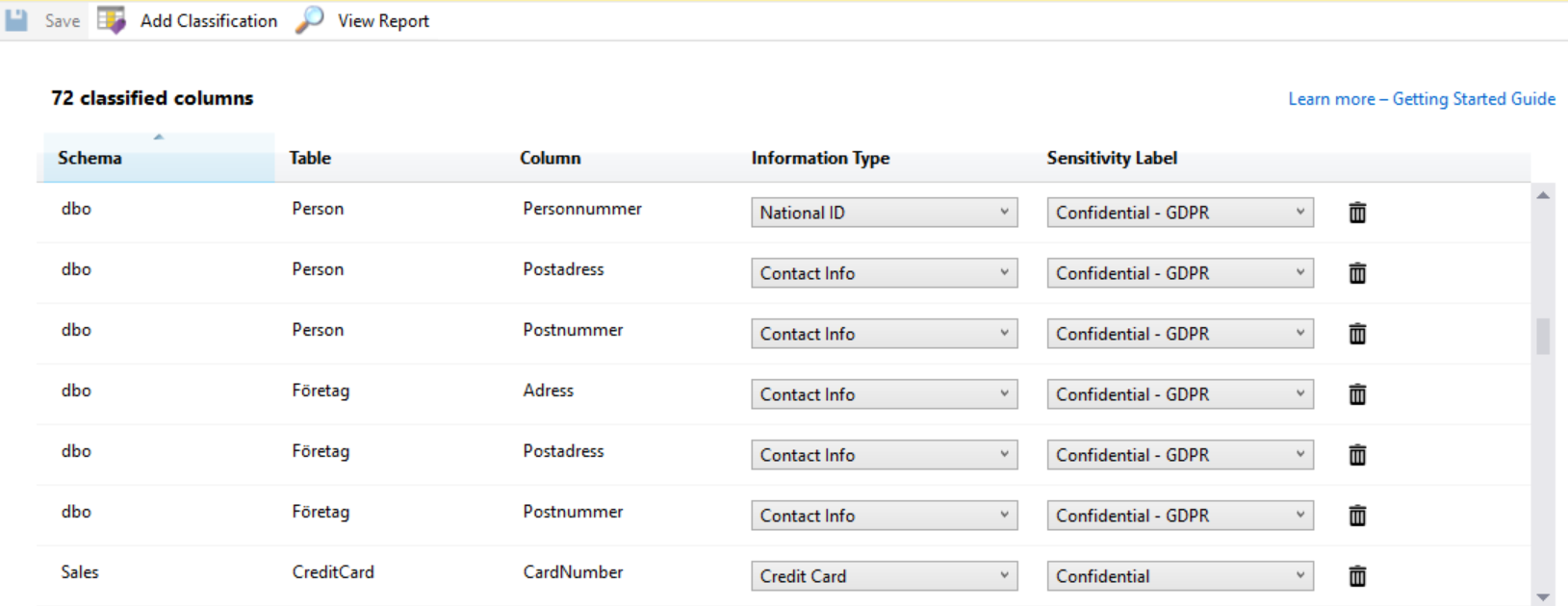
As a final flourish let us go back to the AdventureWorks2016 database and match the XML elements within the HumanResources.JobCandidate table within the Resume column – we can
then use a LIKE match to retrieve Elements against the dictionary table.
--Add some new rows to the dictionary table to use in the XML element demo
('%street%' ,'Contact Info' , 'Confidential - GDPR' ,0),
('%city%' ,'Contact Info' , 'Confidential - GDPR' ,0),
('%postal%' ,'Contact Info' , 'Confidential - GDPR' ,1),
('%zip%' ,'Contact Info' , 'Confidential - GDPR' ,1),
('%Addr%' ,'Contact Info' , 'Confidential - GDPR' ,1),
('%Telephone%' ,'Contact Info' , 'Confidential - GDPR' ,1)
-- Inspiration from this post - thanks Aaronaught
-- https://stackoverflow.com/questions/2266132/how-can-i-get-a-list-of-element-names-from-an-xml-value-in-sql-server
;WITH Xml_CTE AS
(
SELECT
CAST('/' + node.value('fn:local-name(.)',
'varchar(100)') AS varchar(100)) AS name,
node.query('*') AS children
FROM HumanResources.JobCandidate
CROSS APPLY Resume.nodes('/*') AS roots(node)
UNION ALL
SELECT
CAST(x.name + '/' +
node.value('fn:local-name(.)', 'varchar(100)') AS varchar(100)),
node.query('*') AS children
FROM Xml_CTE x
CROSS APPLY x.children.nodes('*') AS child(node)
)
SELECT DISTINCT name, replace(XC.name, '/',''),D.*, R.info_type
FROM Xml_CTE XC
INNER JOIN @Dictionary D ON
replace(XC.name, '/','') LIKE D.pattern COLLATE DATABASE_DEFAULT
LEFT OUTER JOIN @infoTypeRanking R
ON (LOWER(R.info_type) = LOWER(D.info_type))
WHERE (D.info_type IS NOT NULL )
OPTION (MAXRECURSION 1000)