A quick SQL Server Management Studio tip should you ever need to edit a lot of…
Jag är tacksam för översättningshjälp av Sven Engvall & och en underhållande utkast från Bing Translate
Inledning
I mitt tidigare inlägg använde jag SQL-profiler för att undersöka hur dataklassificeringsfunktionen fungerar under täcket och vi fick också reda på ett par brister
(tolkar inte XML-data, försöker och misslyckas med att lägga till utökade egenskaper i tabeller i minnet).
Men vi konstaterade att det är möjligt att lägga till relevanta “extended property tags” direkt från backend och att SSMS rapporter och funktioner kommer att plocka upp dem och visa dem som vanligt.
I det här inlägget kommer jag att göra ett förslag på hur man skapar en egen ordbokstabell och använda dessa anpassade värden (på svenska naturligtvis) för att tillhandahålla dataklassificeringsfunktioner för databaser som har kolumnnamn definierade på svenska (eller vilket språk du lägger till i din ordbokstabell). Jag kommer också att försöka skapa lösningar till de begränsningar i funktionen som jag hittade förra gången.
Först av allt kommer vi att behöva ett par tabeller med kolumnnamn på svenska. Här är ett mycket grundläggande exempel (person & företag).
-- Lägg till ett par tabeller med svenska tabell-och kolumnnamn
IF Object_id('dbo.Person') is not null
BEGIN
Drop Table dbo.Person
END
Create Table dbo.Person
(
Efternamn nvarchar(80) NOT NULL
,Förnamn nvarchar(80) NOT NULL
,Födelseort nvarchar(80) NOT NULL
,medborgarskap nvarchar(80) NOT NULL
,Födelseland nvarchar(80) NOT NULL
,Födelsedatum datetime NOT NULL
,Adress nvarchar(80) NOT NULL
,Postadress nvarchar(80) NOT NULL
,Postnummer varchar(10) NOT NULL
,Personnummer varchar(10) NOT NULL
,Kön varchar(8) NOT NULL
)
IF Object_id('dbo.Företag') is not null
BEGIN
Drop Table dbo.Företag
END
Create Table dbo.Företag
(
Namn nvarchar(100) NOT NULL
,Adress nvarchar(80) NOT NULL
,Postadress nvarchar(80) NOT NULL
,Postnummer varchar(10) NOT NULL
,OrgNummer varchar(10)
)
Ordbok
Vi kommer att stjäla låna ordbokstabellen som vårt “sql trace” förra gången visade. Som en parentes tror jag att genom att lägga till en kolumn för språk och sedan filtrera till engelska plus språket i databasens “collation” skulle vara en genväg till mycket bättre prestanda (och färre falska positiva utfall).
Nu behöver vi bara fylla i ordboken. Jag kommer att ta några av de engelska termerna och översätta dem till svenska. Kan inte motstå att lämna stavfel i %mainden%name%
-Jag antar att denna regel inte kommer att slå till så ofta.
Följande rader/regler bör ge oss tillräckligt för att göra en test. En fullständig GDPR-scanning skulle naturligtvis kräva en fylligare ordbok.
('%användarnamn%' ,'Credentials','Confidential' ,1),
('%lösenord%' ,'Credentials','Confidential' ,1),
('%password%' ,'Credentials','Confidential' ,1),
('%emejl%' ,'Contact Info','Confidential - GDPR' ,0),
('%epost%' ,'Contact Info','Confidential - GDPR' ,0),
('%e-mejl%' ,'Contact Info','Confidential - GDPR' ,0),
('%e-post%' ,'Contact Info','Confidential - GDPR' ,0),
('%efter%namn%' ,'Name','Confidential - GDPR' ,0),
('%för%namn%' ,'Name','Confidential - GDPR' ,0),
('%familjenamn%' ,'Name','Confidential - GDPR' ,0),
-- from original dictionary - to show spelling mistake - this isnt how you spell maiden !!!
('%mainden%name%' ,'Name','Confidential - GDPR' ,0),
('%flick%namn%' ,'Name','Confidential - GDPR' ,0),
('%adress%' ,'Contact Info','Confidential - GDPR' ,0),
('%telefon%' ,'Contact Info','Confidential - GDPR' ,1),
('%mobil%' ,'Contact Info','Confidential - GDPR' ,1),
('%postnummer%' ,'Contact Info','Confidential - GDPR' ,1),
('%person%nummer%' ,'National ID','Confidential - GDPR' ,1)
Därefter fylls informationstyps- och känslighetsetikettstabellerna (@InfoTypeRanking @SensitivityLabel). Posterna är samma som tidigare men jag har lagt till en extra kolumn med datatypen uniqueidentifier
för dessa tabeller eftersom dessa krävs från dataklassificerings sidan (men inte rapporten)
Dessa läggs till som utökade egenskaper.
DECLARE @InfoTypeRanking TABLE
(
info_type NVARCHAR(128),
info_type_guid uniqueidentifier default newid(),
ranking INT
)
--Om vi får flera träffa kommer vi att tillämpa den lägsta rankningen först
--Så om en kolumn matchar på både namn och kreditkort det kommer att klassificeras som namn
--Dina prioriteringar kan skilja sig från Microsofts
INSERT INTO @InfoTypeRanking (info_type, ranking)
VALUES
('Networking', 100),
('Contact Info', 200),
('Credentials', 300),
('Name', 400),
('National ID', 500),
('SSN', 600),
('Credit Card', 700),
('Banking', 800),
('Financial', 900),
('Health', 1000),
('Date Of Birth', 1100),
('Other', 1200)
DECLARE @SensitivityLabel TABLE
(
sensitivity_label NVARCHAR(128),
sensitivity_label_guid uniqueidentifier default newid()
)
INSERT @SensitivityLabel (sensitivity_label)
SELECT distinct sensitivity_label from @Dictionary
Om du vill veta mer om utökade egenskaper hänvisar jag till följande artikel
https://www.Red-Gate.com/simple-Talk/SQL/Database-Delivery/Scripting-Description-Database-tables-using-Extended-Properties/
Observera att Phil använder JSON-formatering för sina utökade egenskaper som skulle tillåta oss att lagra flera utökade egenskap per kolumn (men skulle skapa problem med kompatibilitet med tidigare versioner än SQL Server 2016).
Beräkna resultatet
Sedan fylls @ClassifcationResultstabellen med hjälp av den exakta Microsoft-koden. Nu behöver vi bara använda ett gemensamt tabelluttryck för att generera anrop till sp_addextendedproperty för att tagga kolumner som har identifierats. Så nu är det bara att kopiera koden och klistra in i en nytt SSMS-fönster och ansluten till rätt databas och exekvera.
DECLARE @ClassifcationResults TABLE
(
schema_name NVARCHAR(128),
table_name NVARCHAR(128),
column_name NVARCHAR(128),
info_type NVARCHAR(128),
sensitivity_label NVARCHAR(128),
ranking INT,
can_be_numeric BIT
)
INSERT INTO @ClassifcationResults
SELECT DISTINCT S.NAME AS schema_name,
T.NAME AS table_name,
C.NAME AS column_name,
D.info_type,
D.sensitivity_label,
R.ranking,
D.can_be_numeric
FROM sys.schemas S
INNER JOIN sys.tables T
ON S.schema_id = T.schema_id
INNER JOIN sys.columns C
ON T.object_id = C.object_id
INNER JOIN sys.types TP
ON C.system_type_id = TP.system_type_id
LEFT OUTER JOIN @Dictionary D
ON (D.pattern NOT LIKE '%[%]%' AND LOWER(C.name) = LOWER(D.pattern) COLLATE DATABASE_DEFAULT) OR
(D.pattern LIKE '%[%]%' AND LOWER(C.name) LIKE LOWER(D.pattern) COLLATE DATABASE_DEFAULT)
LEFT OUTER JOIN @infoTypeRanking R
ON (R.info_type = D.info_type)
WHERE (D.info_type IS NOT NULL ) AND
NOT (D.can_be_numeric = 0 AND TP.name IN ('bigint','bit','decimal','float','int','money','numeric','smallint','smallmoney','tinyint'))
; WITH Class AS
(
SELECT
ROW_NUMBER() OVER (ORDER BY MR.schema_name, MR.table_name, MR.column_name) as rnum,
CR.schema_name AS schema_name,
CR.table_name AS table_name,
CR.column_name AS column_name,
OBJECTPROPERTY(OBJECT_ID(N''+CR.schema_name+'.'+CR.table_name+''),'TableIsMemoryOptimized') as IsInMemory,
CR.info_type AS information_type_name,
convert(varchar(50), ITR.info_type_guid) as info_type_guid,
CR.sensitivity_label AS sensitivity_label_name,
convert(varchar(50), SL.sensitivity_label_guid) as sensitivity_label_guid
FROM @ClassifcationResults CR
INNER JOIN
(
SELECT
schema_name,
table_name,
column_name,
MIN(ranking) AS min_ranking
FROM
@ClassifcationResults
GROUP BY
schema_name,
table_name,
column_name
) MR
ON CR.schema_name = MR.schema_name
AND CR.table_name = MR.table_name
AND CR.column_name = MR.column_name
AND CR.Ranking = MR.min_ranking
JOIN @InfoTypeRanking ITR ON
ITR.info_type = CR.info_type
JOIN @SensitivityLabel SL ON
SL.sensitivity_label = CR.sensitivity_label
)
— uncomment and run the below if you want a report
— rather than the calls to add the extended properties
–SELECT
–C.schema_name,
–C.table_name,
–C.column_name,
–OBJECTPROPERTY(OBJECT_ID(N''+C.schema_name+'.'+C.table_name+''),'TableIsMemoryOptimized') as IsInMemory,
–C.info_type AS information_type_name,
–C.sensitivity_label AS sensitivity_label_name,
SELECT rnum, 1 as subsort,
'EXEC sp_addextendedproperty @name = N''sys_information_type_name'', @value = '''+C.information_type_name+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';' as xp1
FROM Class C
UNION ALL
SELECT rnum, 2,
'EXEC sp_addextendedproperty @name = N''sys_information_type_id'', @value = '''+C.info_type_guid+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
UNION ALL
SELECT rnum, 3,
'EXEC sp_addextendedproperty @name = N''sys_sensitivity_label_name'', @value = '''+C.sensitivity_label_name+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
UNION ALL
SELECT rnum, 4,
'EXEC sp_addextendedproperty @name = N''sys_sensitivity_label_id'', @value = '''+C.sensitivity_label_guid+''', '+
'@level0type = N''Schema'', @level0name = '''+C.schema_name+''', '+
'@level1type = N''Table'', @level1name = '''+C.table_name+''','+
'@level2type = N''Column'', @level2name = '''+C.column_name+''';'
FROM Class C
— We can't add extended properties to InMemory tables so lets filter those out
WHERE IsInMemory = 0
order by rnum asc, subsort
När jag sedan öppnar dataklassificeringsfönstret ser jag matchande kolumner korrekt märkta och på samma sätt som i rapporten.
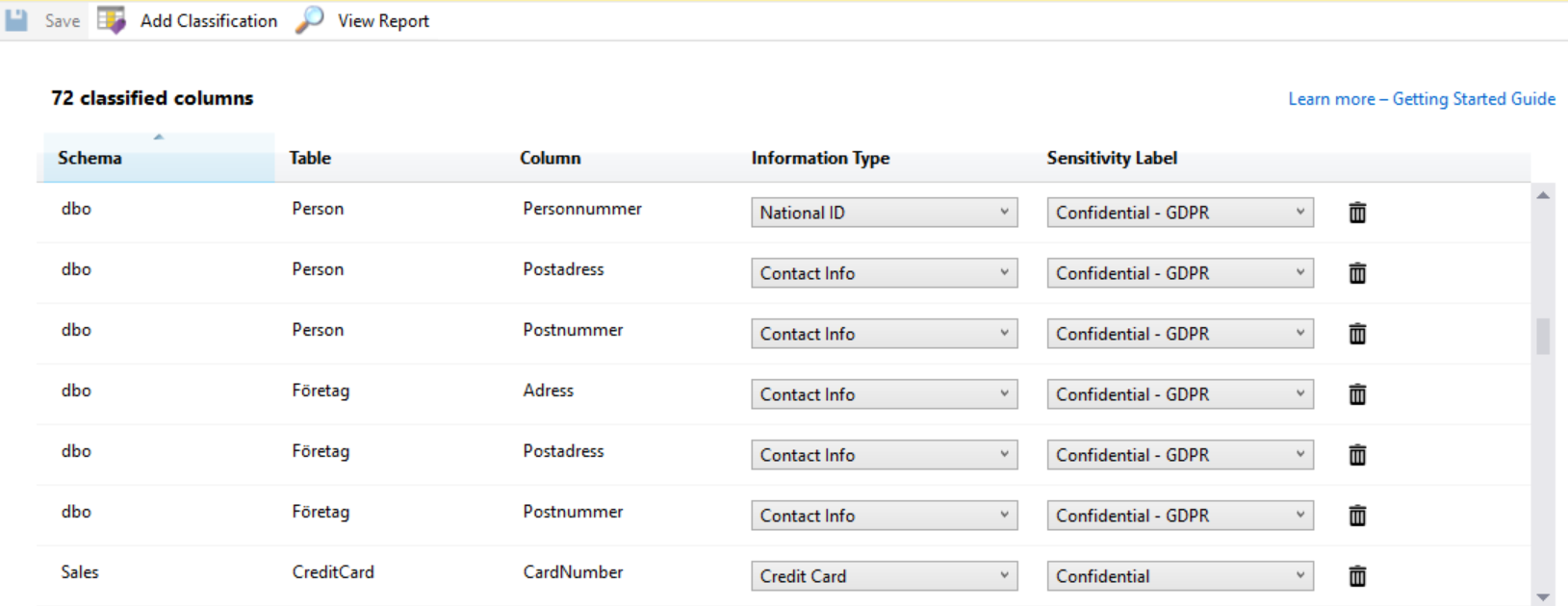
Som en sista kontroll, låt oss gå tillbaka till AdventureWorks2016 databasen och matcha XML-elementen i HumanResources. Resume-kolumnen i JobCandidate-tabellen kan användas till en likadan matchning för att hämta element mot ordbokstabellen.
-- Add some new rows to the dictionary table to use in the XML element demo
('%street%' ,'Contact Info' , 'Confidential – GDPR' ,0),
('%city%' ,'Contact Info' , 'Confidential – GDPR' ,0),
('%postal%' ,'Contact Info' , 'Confidential – GDPR' ,1),
('%zip%' ,'Contact Info' , 'Confidential – GDPR' ,1),
('%Addr%' ,'Contact Info' , 'Confidential – GDPR' ,1),
('%Telephone%' ,'Contact Info' , 'Confidential – GDPR' ,1)
-- Inspiration from this post – thanks Aaronaught
-- https://stackoverflow.com/questions/2266132/how-can-i-get-a-list-of-element-names-from-an-xml-value-in-sql-server
;WITH Xml_CTE AS
(
SELECT
CAST('/' + node.value('fn:local-name(.)',
'varchar(100)') AS varchar(100)) AS name,
node.query('*') AS children
FROM HumanResources.JobCandidate
CROSS APPLY Resume.nodes('/*') AS roots(node)
UNION ALL
SELECT
CAST(x.name + '/' +
node.value('fn:local-name(.)', 'varchar(100)') AS varchar(100)),
node.query('*') AS children
FROM Xml_CTE x
CROSS APPLY x.children.nodes('*') AS child(node)
)
SELECT DISTINCT name, replace(XC.name, '/',''),D.*, R.info_type
FROM Xml_CTE XC
INNER JOIN @Dictionary D ON
replace(XC.name, '/','') LIKE D.pattern COLLATE DATABASE_DEFAULT
LEFT OUTER JOIN @infoTypeRanking R
ON (LOWER(R.info_type) = LOWER(D.info_type))
WHERE (D.info_type IS NOT NULL )
OPTION (MAXRECURSION 1000)